Analyzing the MSTIS simulation
Included in this notebook:
Opening files for analysis
Rates, fluxes, total crossing probabilities, and condition transition probabilities
Per-ensemble properties such as path length distributions and interface crossing probabilities
Move scheme analysis
Replica exchange analysis
Replica move history tree visualization
Replaying the simulation
MORE TO COME! Like free energy projections, path density plots, and more
NOTE: This notebook uses our old analysis approach. See the “new analysis” appendix notebook for details on how to customize analysis.
[1]:
from __future__ import print_function
[2]:
# If our large test file is available, use it. Otherwise, use file generated
# from toy_mstis_2_run.ipynb. This is so the notebook can be used in testing.
import os
test_file = "../toy_mstis_1k_OPS1.nc"
filename = test_file if os.path.isfile(test_file) else "mstis.nc"
print("Using file `"+ filename + "` for analysis")
Using file `mstis.nc` for analysis
[3]:
%matplotlib inline
import matplotlib.pyplot as plt
import openpathsampling as paths
import numpy as np
[4]:
%%time
storage = paths.Storage(filename, mode='r')
CPU times: user 3.37 s, sys: 634 ms, total: 4.01 s
Wall time: 4.04 s
[5]:
# the following works with the old file we use in testing; the better way is:
# mstis = storage.networks['mstis'] # when objects are named, use the name
mstis = storage.networks.first
Reaction rates
TIS methods are especially good at determining reaction rates, and OPS makes it extremely easy to obtain the rate from a TIS network.
Note that, although you can get the rate directly, it is very important to look at other results of the sampling (illustrated in this notebook and in notebooks referred to herein) in order to check the validity of the rates you obtain.
By default, the built-in analysis calculates histograms the maximum value of some order parameter and the pathlength of every sampled ensemble. You can add other things to this list as well, but you must always specify histogram parameters for these two. The pathlength is in units of frames.
[6]:
mstis.hist_args['max_lambda'] = { 'bin_width' : 0.05, 'bin_range' : (0.0, 0.5) }
mstis.hist_args['pathlength'] = { 'bin_width' : 5, 'bin_range' : (0, 150) }
[7]:
%%time
mstis.rate_matrix(storage.steps)
/Users/dwhs/Dropbox/pysrc/openpathsampling/openpathsampling/high_level/network.py:710: FutureWarning: set_value is deprecated and will be removed in a future release. Please use .at[] or .iat[] accessors instead
rate)
CPU times: user 7h 16min 42s, sys: 38min 29s, total: 7h 55min 12s
Wall time: 17h 5min 6s
[7]:
| A | B | C | |
|---|---|---|---|
| A | NaN | 0.00216107 | 0.00187706 |
| B | 0.00117093 | NaN | 0.00119613 |
| C | 0.001321 | 0.00186286 | NaN |
The self-rates (the rate of returning the to initial state) are undefined, and return not-a-number.
The rate is calculated according to the formula:
where \(\phi_{A,0}\) is the flux from state A through its innermost interface, \(P(B|\lambda_m)\) is the conditional transition probability (the probability that a path which crosses the interface at \(\lambda_m\) ends in state B), and \(\prod_{i=0}^{m-1} P(\lambda_{i+1} | \lambda_i)\) is the total crossing probability. We can look at each of these terms individually.
Total crossing probability
[8]:
stateA = storage.volumes["A"]
stateB = storage.volumes["B"]
stateC = storage.volumes["C"]
[9]:
tcp_AB = mstis.transitions[(stateA, stateB)].tcp
tcp_AC = mstis.transitions[(stateA, stateC)].tcp
tcp_BC = mstis.transitions[(stateB, stateC)].tcp
tcp_BA = mstis.transitions[(stateB, stateA)].tcp
tcp_CA = mstis.transitions[(stateC, stateA)].tcp
tcp_CB = mstis.transitions[(stateC, stateB)].tcp
plt.plot(tcp_AB.x, tcp_AB, '-r')
plt.plot(tcp_CA.x, tcp_CA, '-k')
plt.plot(tcp_BC.x, tcp_BC, '-b')
plt.plot(tcp_AC.x, tcp_AC, '-g') # same as tcp_AB in MSTIS
[9]:
[<matplotlib.lines.Line2D at 0x12c5c3390>]
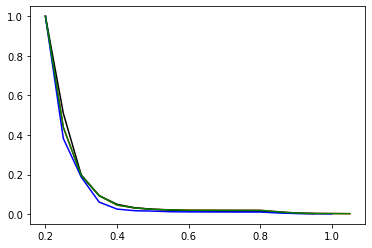
We normally look at these on a log scale:
[10]:
plt.plot(tcp_AB.x, np.log(tcp_AB), '-r')
plt.plot(tcp_CA.x, np.log(tcp_CA), '-k')
plt.plot(tcp_BC.x, np.log(tcp_BC), '-b')
plt.xlim(0.0, 1.0)
[10]:
(0.0, 1.0)
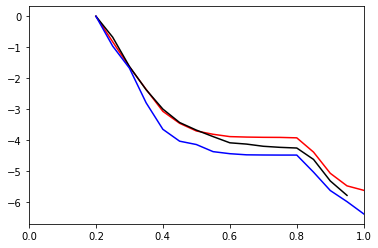
Now, in case you want to know the total crossing probabability at each interface (for example, to use as a bias in an SRTIS calculation):
[11]:
# TODO: MOVE THESE TO A METHOD INSIDE THE CODE; MAKE THEM WORK WITH NEW ANALYSIS
[12]:
import pandas as pd
def crossing_probability_table(transition):
tcp = transition.tcp
interface_lambdas = transition.interfaces.lambdas
values = [tcp(x) for x in interface_lambdas]
return pd.Series(values, index=interface_lambdas, name=transition.name)
[13]:
def outer_crossing_probability(transition):
tcp = transition.tcp
interface_outer_lambda = transition.interfaces.lambdas[-1]
return tcp(interface_outer_lambda)
[14]:
crossing_probability_table(mstis.from_state[stateA])
[14]:
0.2 1.000000
0.3 0.196129
0.4 0.046583
Name: Out A, dtype: float64
[15]:
outer_crossing_probability(mstis.from_state[stateA])
[15]:
0.04658301849747119
[16]:
tcp_AB(mstis.from_state[stateA].interfaces.lambdas[-1])
[16]:
0.04658301849747119
[17]:
tcp_A = mstis.from_state[stateA].tcp
Flux
Here we also calculate the flux contribution to each transition. The flux is calculated based on
[18]:
flux_dict = {
(transition.stateA, transition.interfaces[0]): transition._flux
for transition in mstis.transitions.values()
}
flux_dict
[18]:
{(<openpathsampling.volume.CVDefinedVolume at 0x1294c95f8>,
<openpathsampling.volume.CVDefinedVolume at 0x1294d45f8>): 0.2012342366514623,
(<openpathsampling.volume.CVDefinedVolume at 0x1294c9d30>,
<openpathsampling.volume.CVDefinedVolume at 0x1227e0b38>): 0.20868484148832256,
(<openpathsampling.volume.CVDefinedVolume at 0x1294c9c88>,
<openpathsampling.volume.CVDefinedVolume at 0x129a095f8>): 0.2328636255075233}
[19]:
paths.analysis.tis.flux_matrix_pd(flux_dict)
[19]:
State Interface
A 0.0<opA<0.2 0.201234
B 0.0<opB<0.2 0.208685
C 0.0<opC<0.2 0.232864
Name: Flux, dtype: float64
Conditional transition probability
[20]:
state_names = [s.name for s in mstis.states]
outer_ctp_matrix = pd.DataFrame(columns=state_names, index=state_names)
for state_pair in mstis.transitions:
transition = mstis.transitions[state_pair]
outer_ctp_matrix.at[state_pair[0].name, state_pair[1].name] = transition.ctp[transition.ensembles[-1]]
outer_ctp_matrix
[20]:
| A | B | C | |
|---|---|---|---|
| A | NaN | 0.230536 | 0.200239 |
| B | 0.214964 | NaN | 0.219591 |
| C | 0.113278 | 0.159743 | NaN |
[21]:
state_pair_names = {t: "{} => {}".format(t[0].name, t[1].name) for t in mstis.transitions}
ctp_by_interface = pd.DataFrame(index=state_pair_names.values())
for state_pair in mstis.transitions:
transition = mstis.transitions[state_pair]
for ensemble_i in range(len(transition.ensembles)):
state_pair_name = state_pair_names[transition.stateA, transition.stateB]
ctp_by_interface.at[state_pair_name, ensemble_i] = transition.conditional_transition_probability(
storage.steps,
transition.ensembles[ensemble_i]
)
ctp_by_interface
[21]:
| 0 | 1 | 2 | |
|---|---|---|---|
| (A, B) | 0.009900 | 0.039749 | 0.230536 |
| (A, C) | 0.001691 | 0.059599 | 0.200239 |
| (B, A) | 0.008955 | 0.013034 | 0.214964 |
| (B, C) | 0.013432 | 0.044973 | 0.219591 |
| (C, A) | 0.005224 | 0.019750 | 0.113278 |
| (C, B) | 0.004079 | 0.046316 | 0.159743 |
Path ensemble properties
[22]:
hists_A = mstis.transitions[(stateA, stateB)].histograms
hists_B = mstis.transitions[(stateB, stateC)].histograms
hists_C = mstis.transitions[(stateC, stateB)].histograms
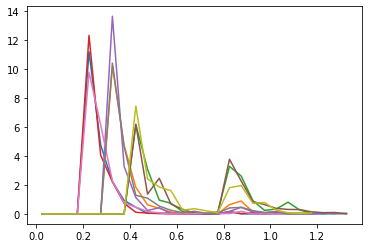
Interface crossing probabilities
We obtain the total crossing probability, shown above, by combining the individual crossing probabilities of
[23]:
hists = {'A': hists_A, 'B': hists_B, 'C': hists_C}
plot_style = {'A': '-r', 'B': '-b', 'C': '-k'}
[24]:
for hist in [hists_A, hists_B, hists_C]:
for ens in hist['max_lambda']:
normalized = hist['max_lambda'][ens].normalized()
plt.plot(normalized.x, normalized)
[25]:
# add visualization of the sum
[26]:
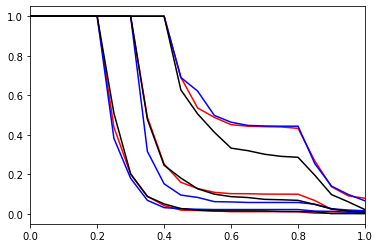
for hist_type in hists:
hist = hists[hist_type]
for ens in hist['max_lambda']:
reverse_cumulative = hist['max_lambda'][ens].reverse_cumulative()
plt.plot(reverse_cumulative.x, reverse_cumulative, plot_style[hist_type])
plt.xlim(0.0, 1.0)
[26]:
(0.0, 1.0)
[27]:
for hist_type in hists:
hist = hists[hist_type]
for ens in hist['max_lambda']:
reverse_cumulative = hist['max_lambda'][ens].reverse_cumulative()
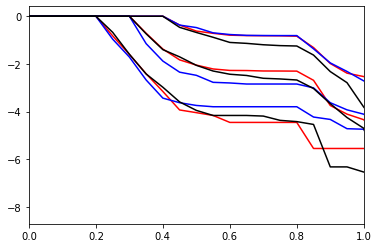
plt.plot(reverse_cumulative.x, np.log(reverse_cumulative), plot_style[hist_type])
plt.xlim(0.0, 1.0)
[27]:
(0.0, 1.0)
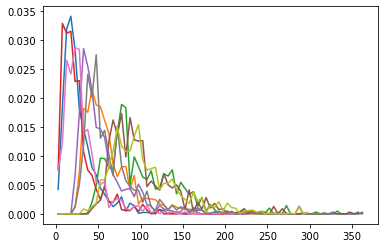
Path length histograms
[28]:
for hist in [hists_A, hists_B, hists_C]:
for ens in hist['pathlength']:
normalized = hist['pathlength'][ens].normalized()
plt.plot(normalized.x, normalized)
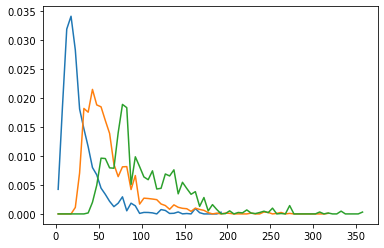
[29]:
for ens in hists_A['pathlength']:
normalized = hists_A['pathlength'][ens].normalized()
plt.plot(normalized.x, normalized)
Sampling properties
The properties we illustrated above were properties of the path ensembles. If your path ensembles are sufficiently well-sampled, these will never depend on how you sample them.
But to figure out whether you’ve done a good job of sampling, you often want to look at properties related to the sampling process. OPS also makes these very easy.
[ ]:
Move scheme analysis
[30]:
scheme = storage.schemes[0]
[31]:
scheme.move_summary(storage.steps)
repex ran 22.284% (expected 22.39%) of the cycles with acceptance 943/4479 (21.05%)
shooting ran 44.502% (expected 44.78%) of the cycles with acceptance 6624/8945 (74.05%)
pathreversal ran 25.687% (expected 24.88%) of the cycles with acceptance 4488/5163 (86.93%)
minus ran 2.900% (expected 2.99%) of the cycles with acceptance 563/583 (96.57%)
ms_outer_shooting ran 4.627% (expected 4.98%) of the cycles with acceptance 643/930 (69.14%)
[32]:
scheme.move_summary(movers='shooting')
OneWayShootingMover Out A 0 ran 5.030% (expected 4.98%) of the cycles with acceptance 854/1011 (84.47%)
OneWayShootingMover Out A 1 ran 5.000% (expected 4.98%) of the cycles with acceptance 753/1005 (74.93%)
OneWayShootingMover Out A 2 ran 5.080% (expected 4.98%) of the cycles with acceptance 655/1021 (64.15%)
OneWayShootingMover Out B 0 ran 4.990% (expected 4.98%) of the cycles with acceptance 814/1003 (81.16%)
OneWayShootingMover Out B 1 ran 5.010% (expected 4.98%) of the cycles with acceptance 745/1007 (73.98%)
OneWayShootingMover Out B 2 ran 4.891% (expected 4.98%) of the cycles with acceptance 643/983 (65.41%)
OneWayShootingMover Out C 0 ran 4.607% (expected 4.98%) of the cycles with acceptance 783/926 (84.56%)
OneWayShootingMover Out C 1 ran 4.826% (expected 4.98%) of the cycles with acceptance 709/970 (73.09%)
OneWayShootingMover Out C 2 ran 5.070% (expected 4.98%) of the cycles with acceptance 668/1019 (65.55%)
[33]:
scheme.move_summary(movers='minus')
Minus ran 0.930% (expected 1.00%) of the cycles with acceptance 180/187 (96.26%)
Minus ran 0.965% (expected 1.00%) of the cycles with acceptance 188/194 (96.91%)
Minus ran 1.005% (expected 1.00%) of the cycles with acceptance 195/202 (96.53%)
[34]:
scheme.move_summary(movers='repex')
ReplicaExchange ran 2.393% (expected 2.49%) of the cycles with acceptance 107/481 (22.25%)
ReplicaExchange ran 2.517% (expected 2.49%) of the cycles with acceptance 137/506 (27.08%)
ReplicaExchange ran 2.468% (expected 2.49%) of the cycles with acceptance 83/496 (16.73%)
ReplicaExchange ran 2.318% (expected 2.49%) of the cycles with acceptance 63/466 (13.52%)
ReplicaExchange ran 2.463% (expected 2.49%) of the cycles with acceptance 114/495 (23.03%)
ReplicaExchange ran 2.502% (expected 2.49%) of the cycles with acceptance 138/503 (27.44%)
ReplicaExchange ran 2.373% (expected 2.49%) of the cycles with acceptance 97/477 (20.34%)
ReplicaExchange ran 2.711% (expected 2.49%) of the cycles with acceptance 98/545 (17.98%)
ReplicaExchange ran 2.537% (expected 2.49%) of the cycles with acceptance 106/510 (20.78%)
[35]:
scheme.move_summary(movers='pathreversal')
PathReversal ran 2.597% (expected 2.49%) of the cycles with acceptance 516/522 (98.85%)
PathReversal ran 2.597% (expected 2.49%) of the cycles with acceptance 468/522 (89.66%)
PathReversal ran 2.582% (expected 2.49%) of the cycles with acceptance 314/519 (60.50%)
PathReversal ran 2.706% (expected 2.49%) of the cycles with acceptance 527/544 (96.88%)
PathReversal ran 2.677% (expected 2.49%) of the cycles with acceptance 504/538 (93.68%)
PathReversal ran 2.408% (expected 2.49%) of the cycles with acceptance 288/484 (59.50%)
PathReversal ran 2.537% (expected 2.49%) of the cycles with acceptance 505/510 (99.02%)
PathReversal ran 2.592% (expected 2.49%) of the cycles with acceptance 492/521 (94.43%)
PathReversal ran 2.463% (expected 2.49%) of the cycles with acceptance 366/495 (73.94%)
PathReversal ran 2.527% (expected 2.49%) of the cycles with acceptance 508/508 (100.00%)
Replica exchange sampling
See the notebook repex_networks.ipynb for more details on tools to study the convergence of replica exchange. However, a few simple examples are shown here. All of these are analyzed with a separate object, ReplicaNetwork.
[36]:
repx_net = paths.ReplicaNetwork(scheme, storage.steps)
Replica exchange mixing matrix
[37]:
repx_net.mixing_matrix()
[37]:
| Out C minus | Out B minus | Out C 0 | Out B 0 | Out C 1 | Out B 1 | Out C 2 | Out B 2 | [UnionEnsemble] | Out A 2 | Out A 1 | Out A 0 | Out A minus | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Out C minus | 0.000000 | 0.000000 | 0.038522 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| Out B minus | 0.000000 | 0.000000 | 0.000000 | 0.037139 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| Out C 0 | 0.038522 | 0.000000 | 0.000000 | 0.000000 | 0.022521 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| Out B 0 | 0.000000 | 0.037139 | 0.000000 | 0.000000 | 0.000000 | 0.016397 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| Out C 1 | 0.000000 | 0.000000 | 0.022521 | 0.000000 | 0.000000 | 0.000000 | 0.027262 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| Out B 1 | 0.000000 | 0.000000 | 0.000000 | 0.016397 | 0.000000 | 0.000000 | 0.000000 | 0.012446 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| Out C 2 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.027262 | 0.000000 | 0.000000 | 0.000000 | 0.020940 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| Out B 2 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.012446 | 0.000000 | 0.000000 | 0.019360 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| [UnionEnsemble] | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.020940 | 0.019360 | 0.000000 | 0.019162 | 0.000000 | 0.000000 | 0.000000 |
| Out A 2 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.019162 | 0.000000 | 0.027064 | 0.000000 | 0.000000 |
| Out A 1 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.027064 | 0.000000 | 0.021138 | 0.000000 |
| Out A 0 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.021138 | 0.000000 | 0.035559 |
| Out A minus | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.035559 | 0.000000 |
Replica exchange graph
The mixing matrix tells a story of how well various interfaces are connected to other interfaces. The replica exchange graph is essentially a visualization of the mixing matrix (actually, of the transition matrix – the mixing matrix is a symmetrized version of the transition matrix).
Note: We’re still developing better layout tools to visualize these.
[38]:
repxG = paths.ReplicaNetworkGraph(repx_net)
repxG.draw('spring')
/Users/dwhs/miniconda3/envs/dev/lib/python3.7/site-packages/networkx/drawing/nx_pylab.py:579: MatplotlibDeprecationWarning:
The iterable function was deprecated in Matplotlib 3.1 and will be removed in 3.3. Use np.iterable instead.
if not cb.iterable(width):
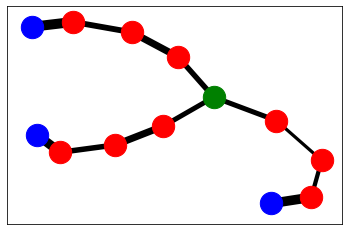
Replica exchange flow
Replica flow is defined as TODO
Flow is designed for calculations where the replica exchange graph is linear, which ours clearly is not. However, we can define the flow over a subset of the interfaces.
[ ]:
Replica move history tree
[39]:
import openpathsampling.visualize as vis
from IPython.display import SVG
[40]:
tree = vis.PathTree(
storage.steps[0:500],
vis.ReplicaEvolution(replica=2, accepted=True)
)
SVG(tree.svg())
[40]:

[41]:
decorrelated = tree.generator.decorrelated
print("We have " + str(len(decorrelated)) + " decorrelated trajectories.")
We have 6 decorrelated trajectories.
Visualizing trajectories
[42]:
# we use the %run magic because this isn't in a package
%run ../resources/toy_plot_helpers.py
background = ToyPlot()
background.contour_range = np.arange(-1.5, 1.0, 0.1)
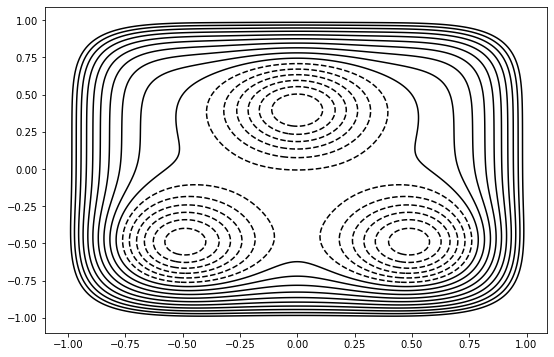
background.add_pes(storage.engines[0].pes)
<Figure size 432x288 with 0 Axes>
[43]:
xval = paths.FunctionCV("xval", lambda snap : snap.xyz[0][0])
yval = paths.FunctionCV("yval", lambda snap : snap.xyz[0][1])
visualizer = paths.StepVisualizer2D(mstis, xval, yval, [-1.0, 1.0], [-1.0, 1.0])
visualizer.background = background.plot()
[44]:
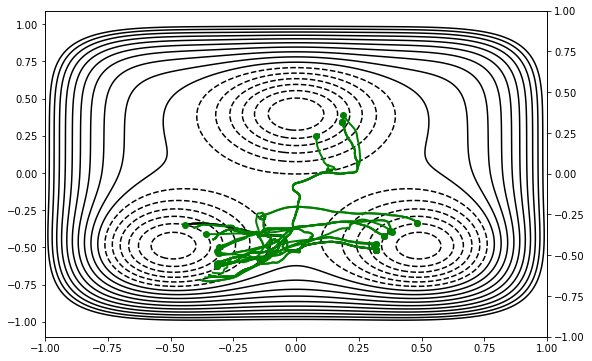
visualizer.draw_samples(list(tree.samples))
[44]:
[45]:
# NBVAL_SKIP
# The skip directive tells our test runner not to run this cell
import time
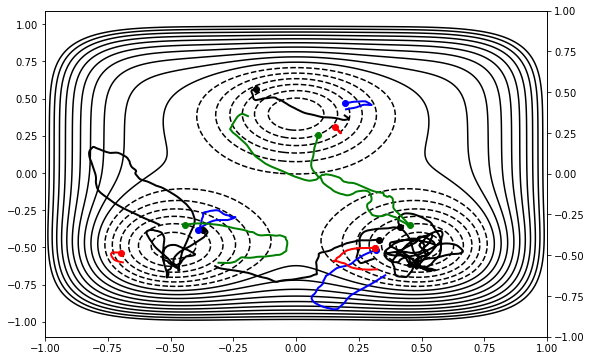
max_step = 10
for step in storage.steps[0:max_step]:
visualizer.draw_ipynb(step)
time.sleep(0.1)
Histogramming data (TODO)
[ ]: